TODO List
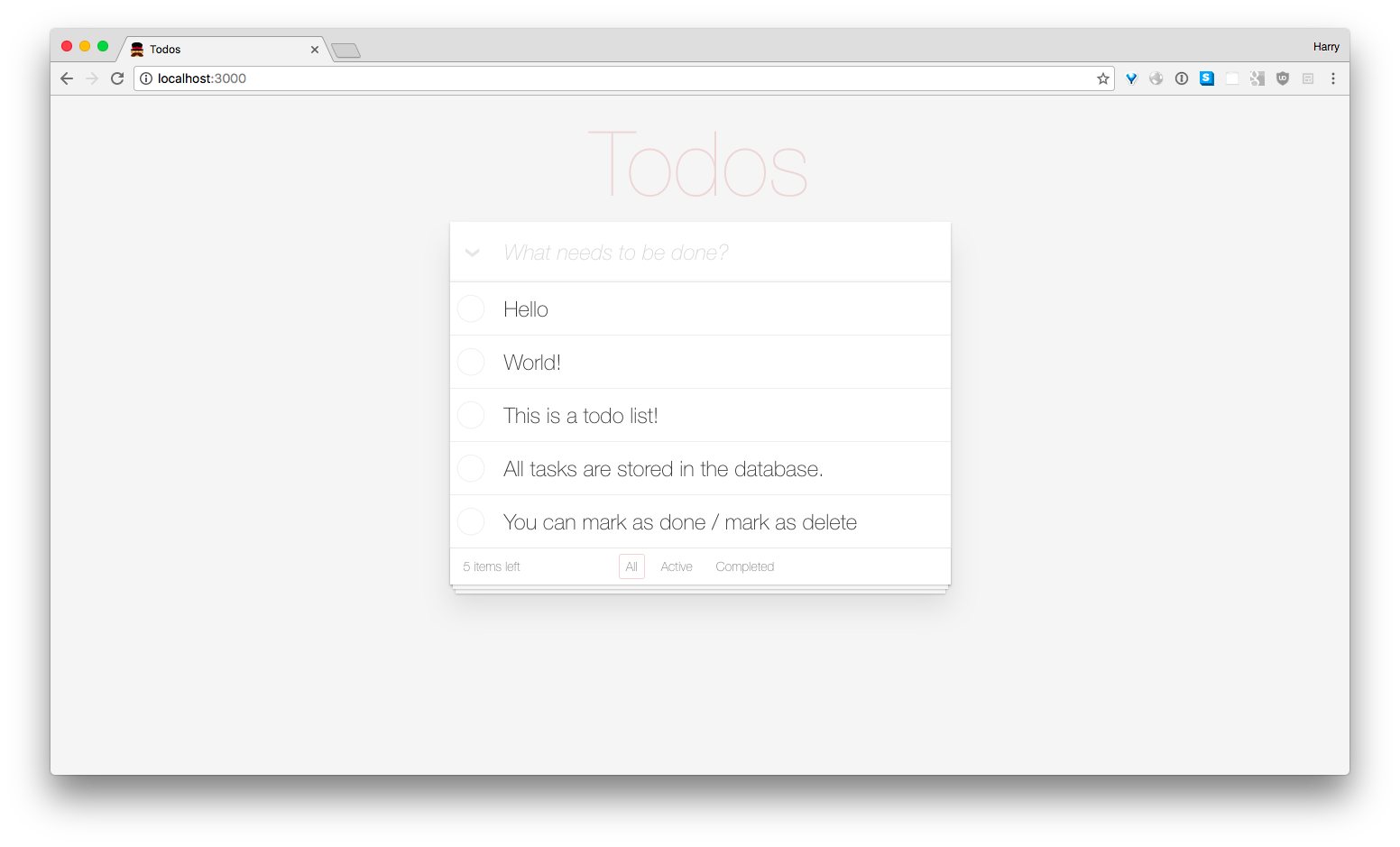
You can try the TODO List app here: https://backendium-todolist.herokuapp.com/.
You are going to build the API backend for the TODO list app in this exercise. We have already done the front-end for you so you can see the effects of your API endpoints.
The source code can be found on Github: https://github.com/hackpacific/backendium_todolist
Requirements / Specifications
Tables / Model
Tasks
- Attributes
content: format is stringcompleted: format is boolean; default value is falsetimestamps: format is datetime
- Validations
content: must be present; maximum 200 characters
API Endpoints
GET /tasks
- Controller:
tasks - Action:
index - Description: return all tasks from database
POST /tasks
- Controller:
tasks - Action:
create - Description: create a new task based on given parameters
- Parameter: accept task object with content (i.e.
{ task: { content: "Hello"} })
DELETE /tasks/:id
- Controller:
tasks - Action:
destroy - Description: delete a task identified by its object
id - Parameter: accept task object id (i.e.
/tasks/101234)
PUT /tasks/:id/mark_complete
- Controller:
tasks - Action:
mark_complete - Description: update a task to change
completedtotrue - Parameter: accept task object id (i.e.
/tasks/101234/mark_complete)
PUT /tasks/:id/mark_active
- Controller:
tasks - Action:
mark_active - Description: update a task to change
completedtofalse - Parameter: accept task object id (i.e.
/tasks/101234/mark_active)
Step-by-step Guides
Since we are not starting from scratch (instead, you are building on top of an existing repository), you can download / clone the project repo:
Before you clone, make sure you navigate to the folder you want this repository to download to.
$ git clone https://github.com/hackpacific/backendium_todolist_project.git
Cloning into 'backendium_todolist_project'...
remote: Counting objects: 107, done.
remote: Compressing objects: 100% (78/78), done.
remote: Total 107 (delta 4), reused 0 (delta 0), pack-reused 19
Receiving objects: 100% (107/107), 27.13 KiB | 0 bytes/s, done.
Resolving deltas: 100% (6/6), done.
Checking connectivity... done.
Once, you have finished cloning, use $ ls and you should see the folder called backendium_todolist_project which is the repository we are going to use. Navigate into backendium_todolist_project.
Now, you can do another $ ls to see the file structures of backendium_todolist_project.
$ ls
Gemfile README.md app config db log spec vendor
Gemfile.lock Rakefile bin config.ru lib public tmp
The file structure should look very familiar because all Rails projects follow the same conventions and folder structures.
Can we start the server $ rails s already? Well... try it. If it doesn't work, that's because we need to run $ bundle install to install all the Ruby dependencies /gems listed in Gemfile.
$ rails s now and visit localhost:3000. You should see the TODO list app with no tasks. If you try to add tasks, it wouldn't work because we haven't written any backend code yet.
I have written 10 tests / specs for you to follow along to build your API endpoint. Run $ rspec.
Failures:
1) Task.new show not raise an error
Failure/Error:
expect {
Task.new
}.not_to raise_error
expected no Exception, got #<ActiveRecord::StatementInvalid: Could not find table 'tasks'> with backtrace:
...
Finished in 0.04859 seconds (files took 6.1 seconds to load)
10 examples, 10 failures
You currently have 10 specs (examples), which are all failing. Since every time we run $ rspec, it will run all the specs, it will generate a lot of error messages if we have a lot of tests failing. So, instead of running all the tests every time, we can actually specify which tests to run.
For example, since we need to store tasks in the database, we should work with migrations and models first. If we want to run $ rspec for models only, we can run $ rspec spec/models.
You can imagine that
$ rspecis the same as$ rspec specwhich will run all the test in the/specfolder. By going to/spec/models, we are now running less tests.
$ rspec spec/models
FFFFF
Failures:
1) Task .new should not return an error
Failure/Error:
expect {
Task.new
}.not_to raise_error
expected no Exception, got #<NameError: uninitialized constant Task> with backtrace:
...
Finished in 0.02771 seconds (files took 6.4 seconds to load)
5 examples, 5 failures
So, there are 5 failures. Let's try to tackle the first one. The test specifies that it expects no error when I run Task.new, but that's not the case. Looking closely in the log, the error raised was #<NameError: uninitialized constant Task> which means that it cannot find Task. Why? Well, it's expecting the Task model, so we have to make one.
$ rails g model task
invoke active_record
identical db/migrate/20161215092914_create_tasks.rb
create app/models/task.rb
invoke rspec
identical spec/models/task_spec.rb
invoke factory_girl
identical spec/factories/tasks.rb
By default, rails generators will also generate the Rspec file. But, since the spec file already exists, it will prompt to ask if you want to overwrite the spec file.
conflict spec/models/task_spec.rb
Overwrite /Users/harrychen/dev/test/backendium_todolist_project/spec/models/task_spec.rb? (enter "h" for help) [Ynaqdh] n
Say no to overwrite by typing n and pressing enter.
Rails helped us generated 2 files we wanted. The migration file db/migrate/xxxx_create_tasks.rb and the model file app/models/task.rb
In db/migrate/xxxx_create_tasks.rb, we don't need to change anything yet:
class Tasks < ActiveRecord::Migration[5.0]
def change
create_table :tasks do |t|
t.timestamps null: false
end
end
end
In app/models/task.rb, we can leave it as it is for now:
class Task < ApplicationRecord
end
To make sure that our tasks table in the database takes effect. We have to run migration by doing $ rails db:migrate. Don't believe me? You can run $ rspec spec/models first to see what you get.
Remember? Defining the migration to modify the database schema is not enough. You have to execute / run the migrations.
By the way,
$ rspecis your best friend when it comes to API backend development. When you have written good specs, its error messages will guide you through step-by-step on what needs to be done.
$ rails db:migrate
== 20161215092914 CreateTasks: migrating ======================================
-- create_table(:tasks)
-> 0.0015s
== 20161215092914 CreateTasks: migrated (0.0017s) =============================
Okay, now that we have run the migrations, let's test it.
$ rspec spec/models
.FFFF
Failures:
1) Task attributes should include 'content'
Failure/Error:
expect {
task.content
}.not_to raise_error
expected no Exception, got #<NoMethodError: undefined method `content' for #<Task id: nil, created_at: nil, updated_at: nil>> with backtrace:
...
Finished in 0.04048 seconds (files took 3.16 seconds to load)
5 examples, 4 failures
We've Passed First Test!.

You see
.FFFF?.means a pass.Fmeans failure.
Alright, now what's the next step? Well, our tasks table needs to have two different columns: content and completed. So, we need to create a new migration to, again, modify the database schema. If you run $ rspec spec/models, you see that my specs are expecting the same thing.
$ rspec spec/models
.FFFF
Failures:
1) Task attributes should include 'content'
Failure/Error:
expect {
task.content
}.not_to raise_error
expected no Exception, got #<NoMethodError: undefined method `content' for #<Task id: nil, created_at: nil, updated_at: nil>> with backtrace:
2) Task attributes should include 'completed'
Failure/Error:
expect {
task.completed
}.not_to raise_error
expected no Exception, got #<NoMethodError: undefined method `completed' for #<Task id: nil, created_at: nil, updated_at: nil>> with backtrace:
...
5 examples, 4 failures
So, migrations. Let's create a new migration file.
$ rails g migration AddAttributesToTasks
invoke active_record
create db/migrate/xxxx._add_attributes_to_tasks.rb
Why is it called
AddAttributesToTasks? Because I named it to give me semantic meanings. You can name it however you want, but having semantic meaning is recommended.
In db/migrate/xxxx_add_attributes_to_tasks.rb, let's add content as a string and completed as a boolean to the tasks table. We set the default completed to be false because tasks are not completed to begin with.
class AddAttributesToTasks < ActiveRecord::Migration[5.0]
def change
add_column :tasks, :content, :string
add_column :tasks, :completed, :boolean, default: false
end
end
Run your migration.
rails db:migrate
== 20161215094136 AddAttributesToTasks: migrating =============================
-- add_column(:tasks, :content, :string)
-> 0.0059s
-- add_column(:tasks, :completed, :boolean, {:default=>false})
-> 0.0036s
== 20161215094136 AddAttributesToTasks: migrated (0.0097s) ====================
Now, test it again.
$ rspec spec/models
...FF
Failures:
1) Task .create requires the presence of 'content'
Failure/Error:
expect {
Task.create!(content: nil)
}.to raise_error(ActiveRecord::RecordInvalid)
expected ActiveRecord::RecordInvalid but nothing was raised
2) Task .create 'content' should have max 200 chars
Failure/Error:
expect {
Task.create!(content: 'a' * 201)
}.to raise_error(ActiveRecord::RecordInvalid)
expected ActiveRecord::RecordInvalid but nothing was raised
5 examples, 2 failures
2 more tests passed!
So, how do we pass the last 2 tests for the Task model? What's the requirement. Well, here it says Task .create requires the presence of 'content' and Task .create 'content' should have max 200 chars.
We need to define some validations for the Task model.
contentmust be presentcontentmust not exceed 200 characters
In app/models/task.rb, we define these validations:
class Task < ApplicationRecord
validates :content, length: { maximum: 200 }, presence: true
end
$ rspec spec/models should now all pass!
$ rspec spec/models
.....
5 examples, 0 failures
Awesome! So, we have successfully finish building the Task model. We can now store tasks records in the database. The M in the MVC is done. Let's move on to the V and C.
We expect to have 5 endpoints. Let's run $ rspec to see the requirements.
$ rspec
FFFFF.....
Failures:
1) TasksController GET /tasks renders all tasks in JSON
Failure/Error: get :index
ActionController::UrlGenerationError:
No route matches {:action=>"index", :controller=>"tasks"}
...
The first endpoint GET /tasks is missing. This endpoint is used to retrieve all the tasks in our database.
To define an endpoint, remember we always follow this flow:
- define endpoint in routes to receive requests
- create the controller (if it doesn't exist) and the methods
- use the method to process the request
- interact with the database if needed
- give back a response
So, we define the route.
In config/routes.rb,
Rails.application.routes.draw do
...
get 'tasks' => 'tasks#index'
...
end
Test it.
$ rspec
FFFFF.....
Failures:
1) TasksController GET /tasks renders all tasks in JSON
Failure/Error: get :index
AbstractController::ActionNotFound:
The action 'index' could not be found for TasksController
...
We need to add the method. Inside the method, we are retrieving all tasks records with Task.all in an array. We store it in an instance variable @tasks with the @ because we want the views to be able to access this variable. We render the response with the help of jbuilder. render 'tasks/index' points the file app/views/tasks/index.jbuilder.
In app/controllers/tasks_controller.rb,
class TasksController < ApplicationController
def index
@tasks = Task.all
render 'tasks/index' # can be omitted
end
end
In app/views/tasks/index.jbuilder (you need to create this file first since it doesn't exist automatically). @tasks is an array, we need to loop through it to output all the tasks. json.array! helps use to do the iterations. For each iterations, we are constructing the object with id, content, completed and created_at.
json.tasks do
json.array! @tasks do |task|
json.id task.id
json.content task.content
json.completed task.completed
json.created_at task.created_at
end
end
The resulting JSON should look like the following
{
"tasks": [
{
"id": 1,
"content": "Content #1",
"completed": false,
"created_at": "2017-01-01..."
}, {
"id": 2,
"content": "Content #2",
"completed": false,
"created_at": "2017-01-01..."
}
]
}
Now, you can run $ rspec again, and the previous test should pass. We are now down to 4 failures to resolve.
$ rspec
.FFFF.....
Failures:
1) TasksController POST /tasks renders newly created task in JSON
Failure/Error:
post :create, params: {
task: {
content: 'New Task'
}
}
ActionController::UrlGenerationError:
No route matches {:action=>"create", :controller=>"tasks", :task=>{:content=>"New Task"}}
The endpoint POST /tasks is missing. This endpoint is used to create a new task in our database. The endpoint will expect a body like the following:
{
"task": {
"content": "Task Content"
}
}
So, let's define the route.
In config/routes.rb,
Rails.application.routes.draw do
# ...
post 'tasks' => 'tasks#create'
# ...
end
And...define the create method.
In app/controllers/tasks_controller.rb,
class TasksController < ApplicationController
def index
# ...
end
def create
@task = Task.new(task_params)
if @task.save
render 'tasks/create' # can be omitted
end
end
private
def task_params
params.require(:task).permit(:content)
end
end
Let's talk about task_params. It's the Rails way of doing things. task_params specifies that the request parameters need to have a task object which contains the key content. In Rails, we write it like this params.require(:task).permit(:content).
@task = Task.new(task_params) creates a new task object.
.newis different from.create. You have to.savethe new object when you are using.new
Once the @task is created, we must save it to store it the database with @task.save. @task.save will return true if successful, and vice versa.
So we use if @task.save to say that if @task.save is successful, render the jbuilder file render 'tasks/create'.
In app/views/tasks/create.jbuilder (you need to create this file first),
json.task do
json.id @task.id
json.content @task.content
json.completed @task.completed
json.created_at @task.created_at
end
Run $ rspec again. Awesome.
Go to localhost:3000 (remember to start your server). You should now be able to add tasks. If you refresh the page after adding multiple tasks, these tasks should persist (stay there) since they are already in the database.
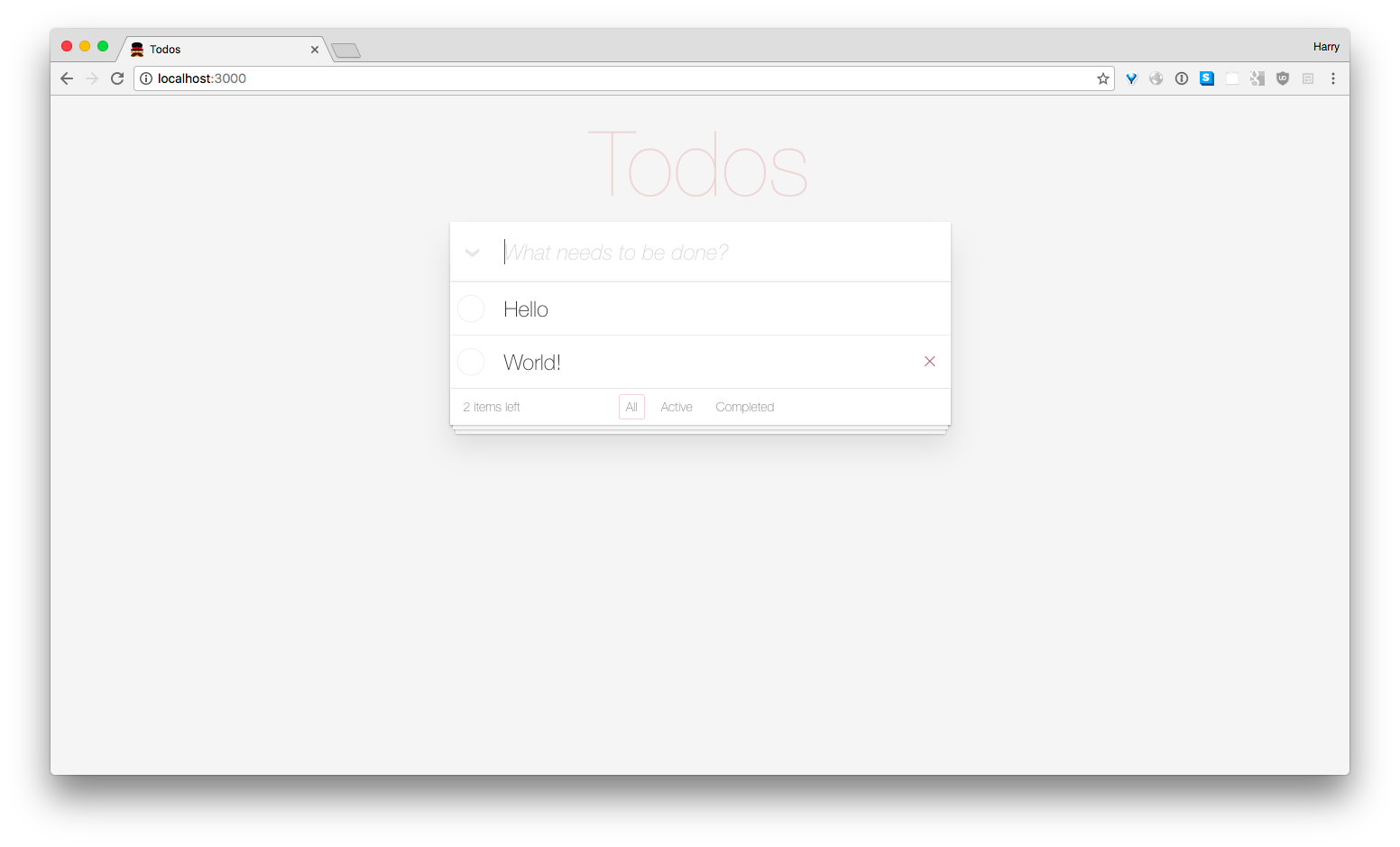
Likewise, we have to define the endpoint DELETE /tasks/:id to destroy / delete a task in our database. The endpoint will expect a id to identify which task to destroy.
In config/routes.rb,
Rails.application.routes.draw do
# ...
delete 'tasks/:id' => 'tasks#destroy'
# ...
end
In app/controllers/tasks_controller.rb,
class TasksController < ApplicationController
def index
# ...
end
def create
# ...
end
def destroy
@task = Task.find_by(id: params[:id])
if @task and @task.destroy
render json: { success: true }
else
render json: { success: false }
end
end
private
# ...
end
params[:id]grabs theid. For example, if the request isDELETE /tasks/101,params[:id]would equal to "101".Task.find_by(id: params[:id])looks for the task with theidif @task and @task.destroymeans that 1) if you can find the task in the database, and 2) if you can destroy it- return a json of
{ success: true }if everything is successful
Run rspec. Another test passed. Go to localhost:3000. You should now be able to DELETE a task!
Alright. Two more endpoints, then we are done. We need the PUT /tasks/:id/mark_complete endpoint to mark a task identified by the given id as completed.
Try it yourself before seeing the answer.
In config/routes.rb,
Rails.application.routes.draw do
# ...
put '/tasks/:id/mark_complete' => 'tasks#mark_complete'
# ...
end
In app/controllers/tasks_controller.rb,
class TasksController < ApplicationController
def index
# ...
end
def create
# ...
end
def destroy
# ...
end
def mark_complete
@task = Task.find_by(id: params[:id])
if @task and @task.update(completed: true)
render 'tasks/mark_complete'
end
end
private
# ...
end
In app/views/tasks/mark_complete.jbuilder,
json.task do
json.id @task.id
json.content @task.content
json.completed @task.completed
json.created_at @task.created_at
json.updated_at @task.updated_at
end
Run Rspec & Test.
And lastly, we need the PUT /tasks/:id/mark_active endpoint to mark a task identified by the given id as NOT completed (basically doing the opposite as the previous endpoint).
Try it yourself before seeing the answer.
In config/routes.rb,
Rails.application.routes.draw do
# ...
put '/tasks/:id/mark_active' => 'tasks#mark_active'
# ...
end
In app/controllers/tasks_controller.rb,
class TasksController < ApplicationController
def index
# ...
end
def create
# ...
end
def destroy
# ...
end
def mark_complete
@task = Task.find_by(id: params[:id])
if @task and @task.update(completed: true)
render 'tasks/update'
end
end
def mark_active
@task = Task.find_by(id: params[:id])
if @task and @task.update(completed: false)
render 'tasks/update'
end
end
private
# ...
end
Here, you can see that the difference between mark_active and mark_complete is where you updated the completed as false instead of true. Everything else is the same. We also renamed app/views/tasks/mark_complete.jbuilder to app/views/tasks/update.jbuilder. Why? Because the two methods can share the same jbuilder view. We don't want redundant code. Remember DRY, Don't Repeat Yourself?
Now run $ rspec
$ rspec
..........
10 examples, 0 failures
All PASSED!
Now, check localhost:3000. All functions should work now!