What is Git?
Git is a version control system. It means that if you are editing a file, you can save a version of the file as snapshots.
Try Git
https://try.github.io/levels/1/challenges/1
What is Git?
Git works on top of existing files and folders. So, you can go to any folder and start using Git.
git init
By default, your computer is not tracking every version of your files. So, if we want to use Git to start tracking versions, we have to initialize it.
Let's take the following example.
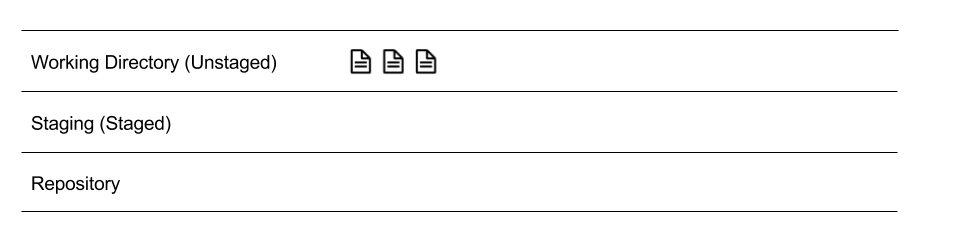
You have three files, each in the Working Directory, which just means your folder. Repository stores the snapshots of files you've taken. And, we will explain Staging later.
To initialize Git in a folder, first go to the folder with cd path/to/folder, then run $ git init to initialize Git.
Untracked Files
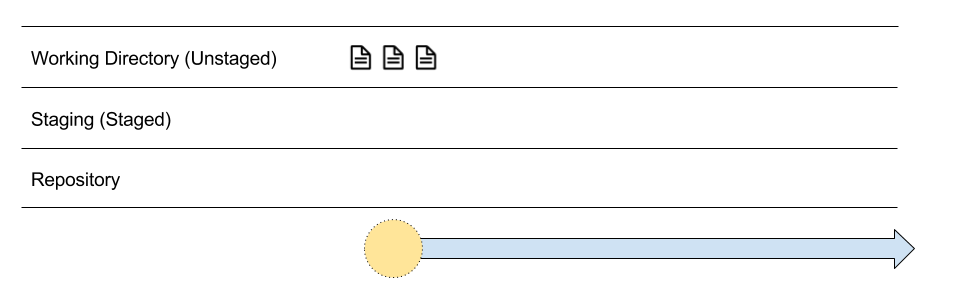
After you have run git init, the timeline of snapshots has been initialized. The yellow dot with dotted borders means that no snapshots have been taken, but if you are to take a snapshot now, that's where it would be placed in the timeline.
So, can we take a snapshot now? Not yet. That's where Staging comes in. Only the files (new or modified) in Staging will be in a snapshot. It's a way for you to control which file or file changes you want to track. Neat, eh?
every new files start with being untracked
Since the three files have never been tracked for changes before, we say that these files are currently untracked.
To put a specific untracked file into Staging (so that we can take a snapshot of it later), do $ git add filename.txt.
- To start tracking a file, do
$ git add filename.txt - If you want to start tracking an entire folder, do
$ git add path/to/folder - If you want to start tracking the current folder, do
$ git add ., where.represents the current folder
In this case, we are going to add all the files in this folder to Staging by using $ git add .
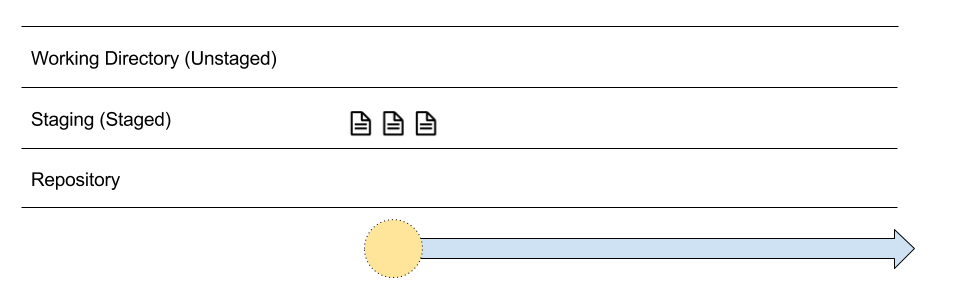
Great, our 3 files have gone from untracked to staged, and we are ready to take a snapshot.
To take a snapshot of all the files currently tracked by Git, make a commit. I have used the word snapshot as an analogy, but the real technical term is commit.
In order to give more context to each snapshot / commit, you can write a commit message. Do $ git commit -m "This is my commit message". -m here is an option provided by the Git command to add the commit message in one single line
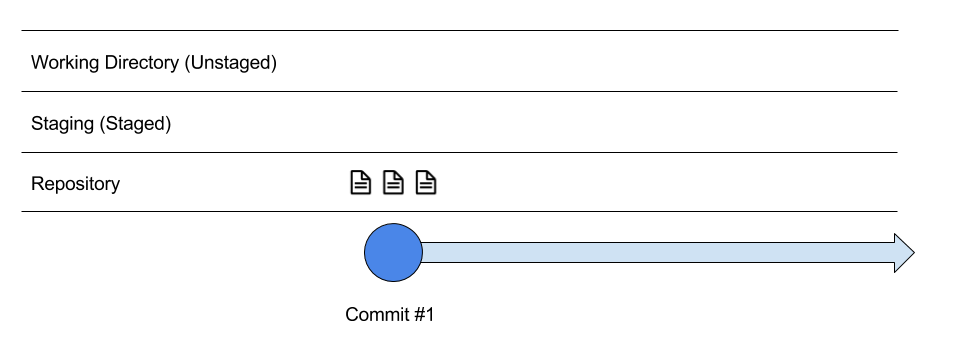
And, there we have our first commit. Likewise, when you are creating new files, they are by default untracked. So, you have to
- start tracking them with
git add - make commit for snapshotting with
git commit
You only need to
git initonce (ever) for a folder. If you need to do it multiple times, you are probably doing something wrong.
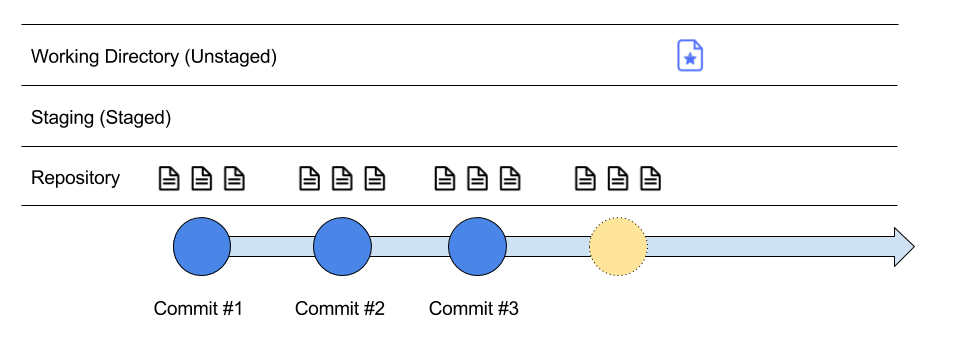
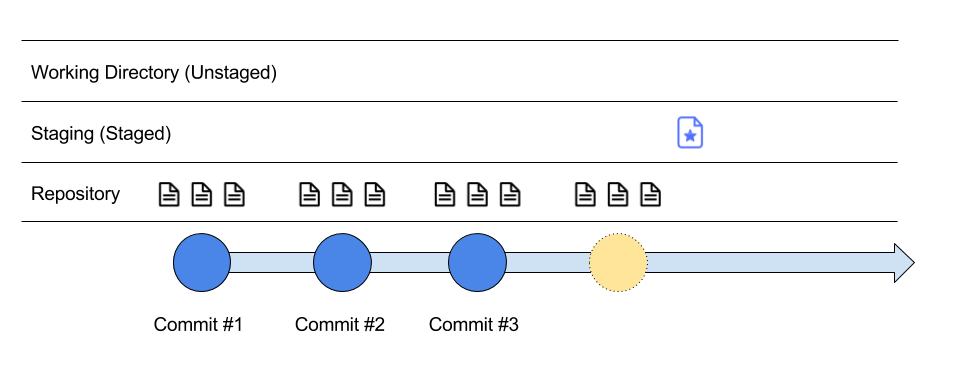
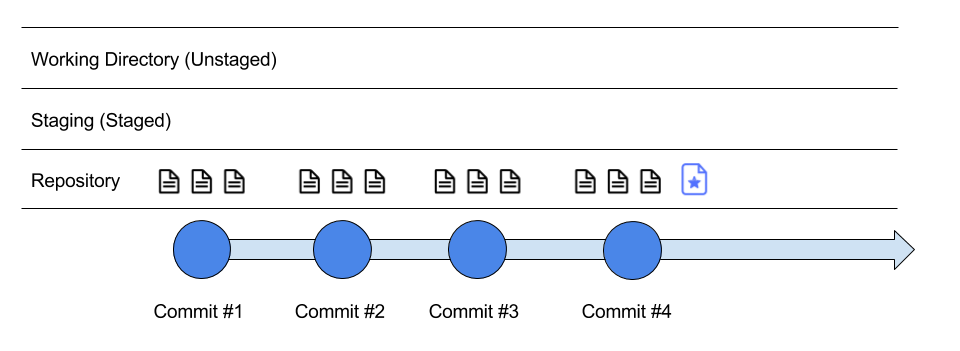
Here, we have created a new file with the star symbol, so call it a star file. We start by adding the star file to staging, so when we make a commit (take a snapshot), it gets stored in the repository (timeline of changes).
Staging for Changes
So, let's say you have started tracking changes for some of your files. What happens when you modify one of the files?
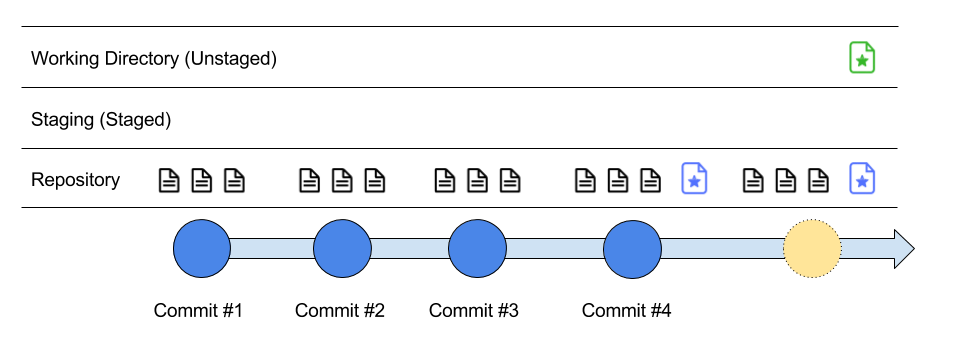
Here, we have modified the star file as it went from blue to green as a representation of change.
Is the star file currently untracked? No. The star file has been marked as tracked since we added it to the repository the first time. But, when we make a modification to the file, it now has a status of being unstaged - meaning we have to explicitly move it to Staging if we want to include it in the next commit (again, snapshot).
once a file has been tracked, if you modify the file, it's unstaged. To stage a file, you also simply use
git add.
So, we stage the star file with $git add star_file.
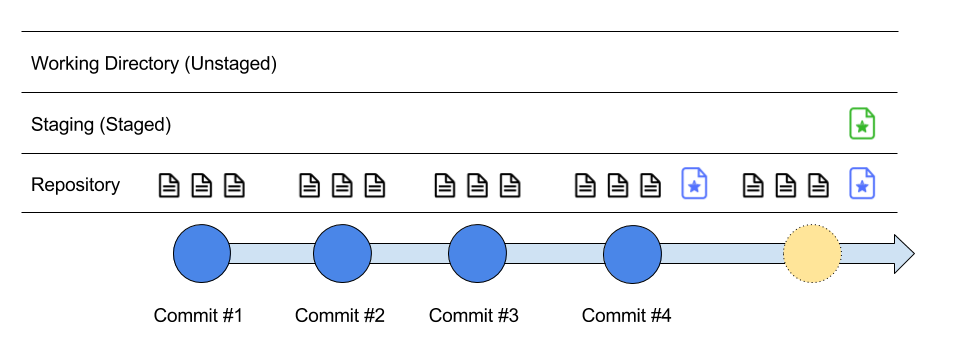
The star file has moved to Staging and is ready for a commit.
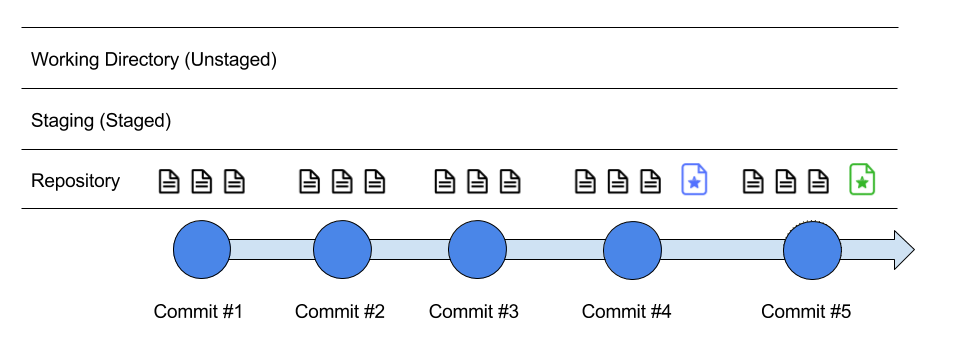
And, if we do $ git commit -m "Modify Star File", the changes will snapshot in the repository timeline.
Git Branch: git branch

A series of commits create what I call a timeline or a log of snapshots. Now, this is great for tracking versions of any given files.
Having one timeline of all the snapshots is cool. But, Git enables you to have multiple timelines, like having multiple universes.
Consider the following:
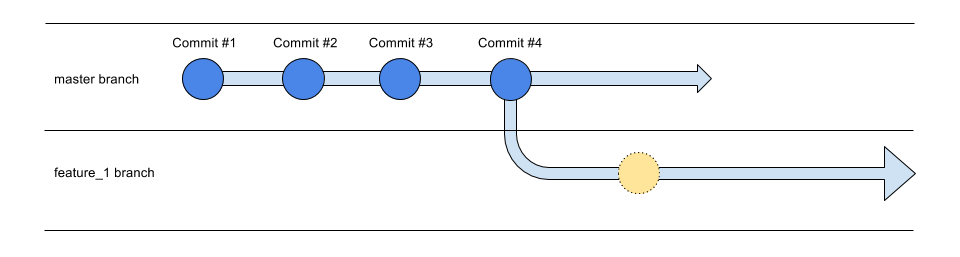
In Git, a timeline (analogically) is technically called a branch. Here, we have 2 branches (2 timelines). One called master, the other named feature_1.
By working on different branches, you are taking different snapshots in different timelines.
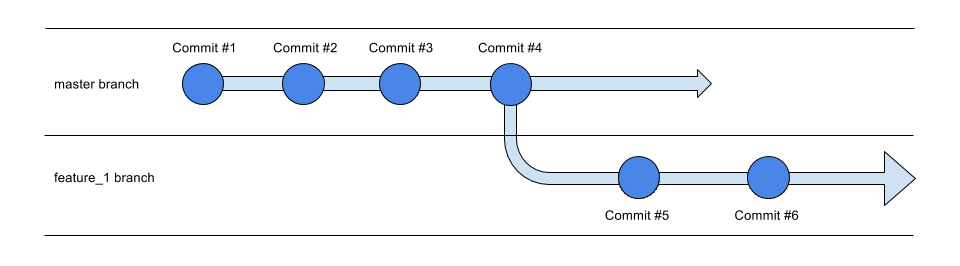
So here, commit #5 and commit #6 only exists in the feature_1 branch, but not the master branch. Why do we want this? Think Drafts.
Conventionally, we use the master branch as main branch. It means all the good things that are ready should be here. Other branches are more like Drafts. They are not ready yet, so their commits should not be in master YET.
Why is this good? We allow developers working in a TEAM to create as many branches as they want to do work.
Git Branches allow team members to create multiple universes, if you might, to experiment and work on, so that they don't mess around and destroy the actual universe we are living in.
We usually call these experimental, draft branches a feature branch. Because most developers will develop a new feature in a separate branch. When the development work is done on a feature branch, we will merge it back to the master branch.
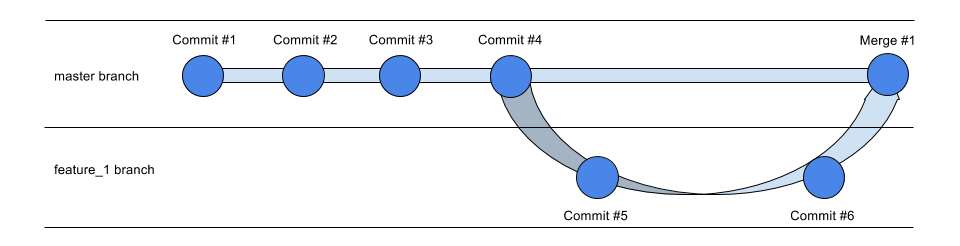
So, let's say feature_1 now looks good and is ready to be used by users. When we merge feature_1 back into master, master will now have both commit #5 and commit #6.
Other commands
- to unstage, use
git reset <file name> - git diff
- git branch
- git branch -d
- git checkout -b
- git checkout
- git remote / git remote add
- git merge
$ git statussee the current status of the version control.- To see all the snapshots / commits you have done, check the logs with
$ git log
https://www.youtube.com/watch?v=OqmSzXDrJBk
Reference: